Regulatory Intelligence Technology
CUBE leverages the latest advances in deep learning to transform unstructured regulatory data into user-specific and actionable regulatory intelligence. We are redefining how compliance professionals manage regulatory change, with advanced natural language processing (NLP), and proprietary classification models to deliver automated regulatory intelligence at scale.
What is RegAI? Why does it matter for compliance?
RegAI is CUBE’s proprietary regulatory AI framework, purpose-built to handle the complexity, volume, and nuance of global financial regulation. Unlike general-purpose AI, RegAI is trained exclusively on regulatory data, enabling it to understand the language, intent, and implications of compliance content at scale.

Relevant Regulatory Intelligence
RegAI dramatically reduces noise by filtering out irrelevant updates, false positives, and missed obligations so that your compliance team sees only the regulatory content that’s truly relevant to your business, mapped directly to your risk profile and operations. This saves valuable time and effort otherwise spent sifting through information, putting the right insights directly at your fingertips when you need them most.

Accelerated Regulatory Understanding
With advanced natural language processing trained on legal and regulatory language, RegAI identifies the key insights within lengthy, complex documents. No more reading through pages upon pages of policy - easily see clear, actionable highlights aligned to your internal framework. This reduces the cognitive load on your compliance team, helping them quickly understand what’s required, without needing to decode complex legal jargon. Instead, you can see instantly what needs to be done and how to do it.
Automated, Intelligent Workflows
RegAI learns from your past decisions and applies semantic understanding to automate key parts of the compliance lifecycle, like classification, mapping, and impact analysis. Over time, the system becomes more precise, more predictive, and more aligned with your processes. This eliminates reliance on manual tasks, reduces the risk of human error, and ensures continuity, even if key team members leave or roles change, because the process is already mapped and repeatable.
RegAI architecture
CUBE combines state-of-the-art machine learning techniques, including computer vision, natural language processing, and graph machine learning, to transform regulatory content into structured, enriched, and actionable intelligence. This enables you to be proactive with your compliance efforts rather than reactive, keeping you one step ahead at all times to minimise risk.
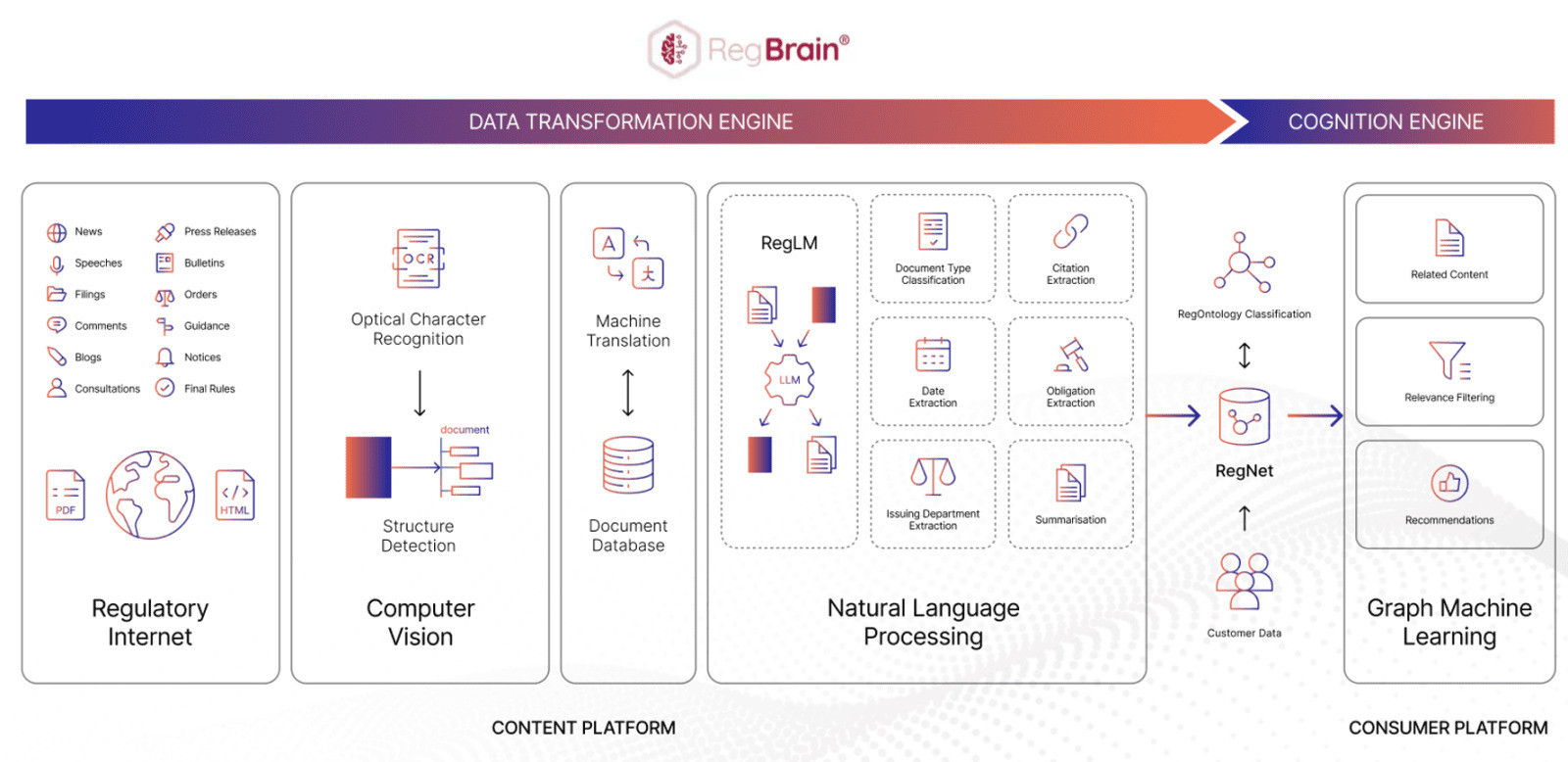
Computer vision
Computer vision models convert text images into machine readable content and reveal structural components; everything from headers to body paragraphs to footers, resulting in a hierarchical document.
Natural language
CUBE applies deep NLP and its proprietary RegLM to translate, classify, and contextualise legal and regulatory content. This model is fine-tuned for a variety of use cases: entity extraction, citation extraction, document type classification, obligation identification, and summarisation.
Graph machine learning
The structured and enriched content is classified and enters our regulatory knowledge graph, along with user data. Graph machine learning techniques leverage the knowledge graph to recommend content to users based upon their actions.
FAQs
-
Regulatory intelligence is the process of collecting, analysing, and applying regulatory data to understand how legal and compliance obligations impact an organisation. It goes beyond basic monitoring by turning raw regulatory information into structured, contextual insights, helping your firm anticipate, interpret, and act on change. With automated regulatory intelligence tools, your compliance teams can streamline this process using AI and machine learning to reduce manual effort, improve accuracy, and stay ahead of evolving global requirements.
-
RegBrain allows clients to apply CUBE’s full AI stack, including agentic AI, summarisation, classification, and enrichment, to their own content. Delivered as APIs or via UI, RegBrain powers faster review, feedback, and action.
RegAI foundations
How we approach the use of Artificial Intelligence
At CUBE, we believe in both transparent and ethical technology. Our proprietary AI is founded upon six interconnected core principles.

Explainable
At CUBE, explainability is essential. We use advanced visualisation techniques and interpretability tools to show users how AI decisions are made, offering full transparency into model logic and reasoning.

Human Input
Our regulatory intelligence combines AI with human expertise. Our data scientists work closely with our regulatory specialists to guide model development, while real-time user feedback loops within the platform to help refine and improve AI performance over time.

Semantic Understanding
CUBE’s NLP models are tuned exclusively on regulatory and legal data, enabling semantic understanding of complex content. This goes beyond keyword matching; our models grasp syntax, legal intent, and contextual meaning, powering intelligent compliance outcomes.

Built for Scale
Our models are designed for scale and can process vast volumes of regulatory updates across multiple jurisdictions, languages, and formats. Deployed via cloud, they scale with demand and support global compliance operations.

Security
Given the high sensitivity of our client data, we have implemented security at three different levels: backend access to our services, frontend access to our services, and our data pipeline. All user data in the cloud is fully anonymised.

Sustainable AI
We recognise the environmental impact of training large AI models, so we focus on curating smaller, high-quality datasets to train smarter, more efficient models. This not only boosts accuracy, but it also reduces our carbon footprint.
Streamline your compliance process with CUBE
By embedding regulatory intelligence into every step of your change management process, RegAI helps you to become proactive rather than reactive, stay ahead of change, reduce manual burden, and transform compliance processes.